

The CLEVER Project is tackling one of the most critical questions in AI for distributed environments: how do we make machine learning resilient when data comes from a wide range of sources—with varying levels of trust?
📍 Presented at the Cloud Edge Continuum Workshop (CEC23), our latest research explores:
🔹 How trust scores—based on data provenance and handling—can weight training data
🔹 Why not all data should be treated equally in AI/ML
🔹 And how Zero Trust principles can improve model performance even when data is “poisoned” or partially unreliable
🧠 Our experiments show that trust-based weighting:
✅ Boosts prediction accuracy
✅ Preserves valuable insights from low-trust data
✅ Outperforms both naïve use of all data and strict exclusion of “untrusted” entries
🔍 This work demonstrates how Data Confidence Fabrics and Trust Algorithms can be harnessed in edge-cloud AI pipelines to build robust and explainable models for the real world.
📈 Figure 1: Trust-based weighting beats both poisoned and overly clean datasets by preserving explanatory power while minimizing model corruption 👇
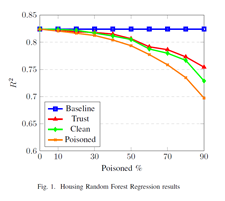
This approach is now being evaluated across CLEVER’s federated learning use cases in heterogeneous edge-cloud environments.
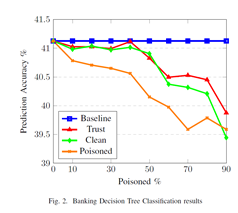
🔗 Explore the CLEVER Project: https://www.cleverproject.eu
🌐 Read the full paper: https://zenodo.org/records/10870611
#CLEVERProject #EdgeComputing #MachineLearning #TrustAI #ZeroTrust #DataConfidence #AIethics #FederatedLearning #Cybersecurity #SmartEdge #AIresearch #CEC23 #CloudEdgeContinuum