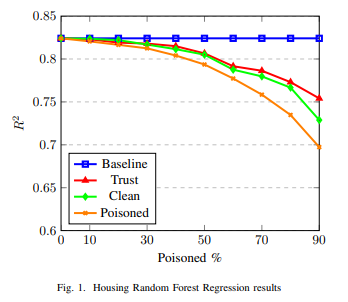
Abstract :In distributed environments, data for Machine Learning (ML) applications may be generated from numerous sources and devices, and traverse a cloud-edge continuum via a variety of protocols, using multiple security schemes and equipment types. While ML models typically benefit from using large training sets, not all data can be equally trusted. In this work, we examine data trust as a factor in creating ML models, and explore an approach using annotated trust metadata to contribute to data weighting in generating ML models. We assess the feasibility of this approach using well-known datasets for both linear regression and problems, demonstrating the benefit of including trust as a factor when using heterogeneous datasets. We discuss the potential benefits of this approach, and the opportunity it presents for improved data utilisation and processing.
https://zenodo.org/records/10870611